
러닝머신 하는 K-공대생
[XAI Reading Log] The All Convolutional Net #1 본문
Date: 2021/09/09
Title: Striving for Simplicity: The All Convolutional Net #1
- Reasons why I read this paper:
Reading a paper explains Layer-wise Relevance Propagation last time, I had have curiosities about backward processs in neural networks explain or visuallize black boxes of neural networks. Also I have experience on visuallizing Convolutional Neural Network using Guided Backpropagation without deep understanding about it. Visuallizing AI is not XAI but they're inter-related. So I choosed this paper to understand Guided Backpropagation and releated theory because I was judged having basic knowledge to read this.
- Today's Reading Purpose:
My purpose is understanding the processes of replacement pooling layer with convolution layer.
- Summary:
This paper says that CNN model which has without complex activation function, max-pooling operations or response normalization can have enough good perforamance. Furthur, they suggest Guided-Backpropagation as a new visuallization method of CNN and compare the before(ex. deconvnet).

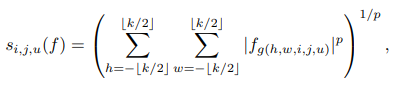

- About pooling layer :
Through pooling layers, we can make features more invariant, easy for optimization and accept large sizes of image as a input. But there is a disadvantage that some feature informations can be vanished after pooling layer which reduces spatial dimensionality.
- Replacement pooling layer with convolution layer :
- We can remove each pooling layer and increase the stride of the convolutional layer that preceded it accordingly.
- We can replace the pooling layer by a normal convolution with stride larger than one (i.e. for a pooling layer with k = 3 and r = 2 we replace it with a convolution layer with corresponding stride and kernel size and number of output channels equal to the number of input channels)

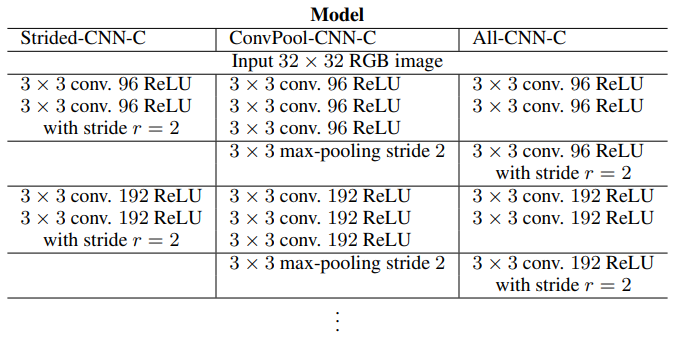
- Classification Results :


My thought:
I was suprised by pretty good results of the alternative model (pool->conv) which has simple architectures. I thought if it could imporve the performance but it doesn't improve performance of CNNs. Interesting points of this paper is also showing us advantages using Guided-Backpropagation which is a way of visuallizing CNN. So I will read this part intensively next reading time. Still writing reading log takes long time and is depending on English dictionary, but it seems to have improved a little bit.
Reference:
- Springenberg, J.T., Dosovitskiy, A., Brox, T., & Riedmiller, M.A. (2015). Striving for Simplicity: The All Convolutional Net. CoRR, abs/1412.6806.
- https://you359.github.io/cnn%20visualization/All-Convnet/
'Machine Learning' 카테고리의 다른 글
| 회피했던 머신러닝 이론들 & 최근 드는 생각 (2) | 2022.01.24 |
|---|---|
| Pygame 을 이용한 딥러닝 모델 시각화 툴 개발 (2) | 2021.12.26 |
| [XAI Reading Log] Layer-Wise Relevance Propagation #2 (1) | 2021.09.02 |
| [XAI Reading Log] Layer-Wise Relevance Propagation #1 (2) | 2021.08.26 |
| Monocular Depth Estimation (0) | 2021.08.18 |



