
러닝머신 하는 K-공대생
[XAI Reading Log] Layer-Wise Relevance Propagation #2 본문
Date: 2021/09/02
Title: On pixel-wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation #2
- Today’s Raeding Purpose:
I tried to understand Pixel-wise Decomposition as a general concept last time. I wondered how decompose prediction or output(f(x)) of Deep Neural Network and define relevance. I will understand the detailed meaning of each processes of LRP and Pixel-wise Decomposition for Multilayer Networks. This time, I'll write Reading Log focused on meaning of formulas related LRP.
- Layer-wise Relevance Propagation:

This Paper denotes as layer-wise relevance propagation as a general concept for the purpose of achieving a pixel-wise decomposition as a general concept for the purpose of achieving a pixel-wise decomposition. Method which is satisfying the constraints will be considered as a layer-wise relevance propagation.
- Constraints of LRP:
1) Sum of relevance of each layers are conservative. (as the same with model output f(x))

2) Total node relevance must be the equal to the sum of all relevance messages incoming.

+ Constraint 2) is a sufficient condition in order to ensure Constraint 1 holds.

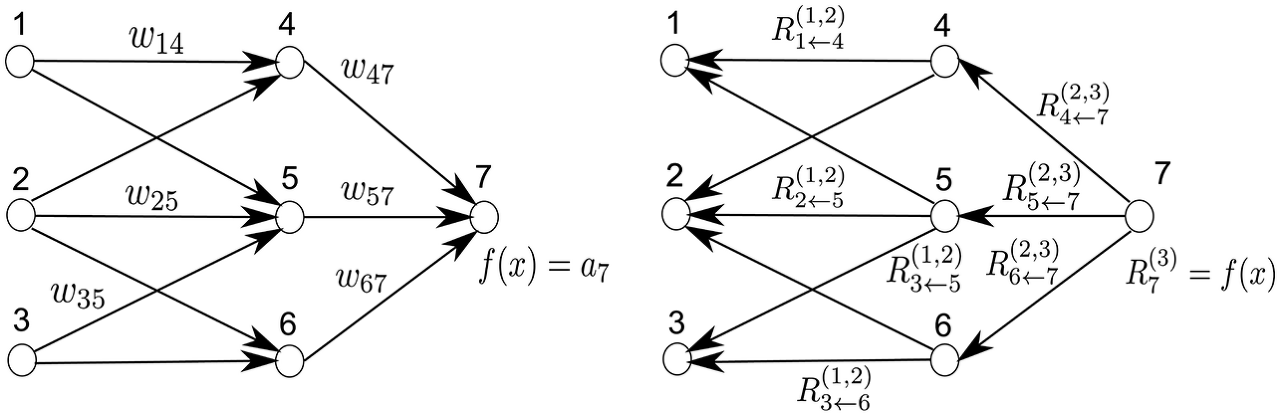
- Define Message and Explict formula for layer-wise relevance propagation:
LRP should reflects the messages passed during classification time. During classification time, a neuron i inputs ai*wik to neuron k, provided that i has a forward connection to k.
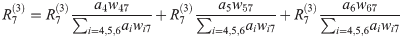

We can express equation like above and obtain explict formula as

- Talor-Type decomposition:
Alternative approcah of decomposition for a general differentiable predictor f is first order Talyer approximation. We can think relevance score as the degree of change in output f as input x changes. And this can be obtained by df/dx.
For input x which is V-dimensional space, Talyer approximation can be written as
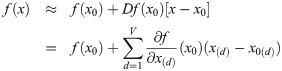
We can find suitable x_0 which f(x_0) = 0 mathematically using feature of Talyer approximation. Then, output f(x) can be decomposed of relevance score.
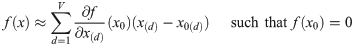
For more information about this:
- https://angeloyeo.github.io/2019/08/17/Layerwise_Relevance_Propagation.html
- Explaining NonLinear Classification Decisions with Deep Taylor Decomposition, Montavon et al., 2015)
- Pixel-wise Decomposition for Multilayer Networks:
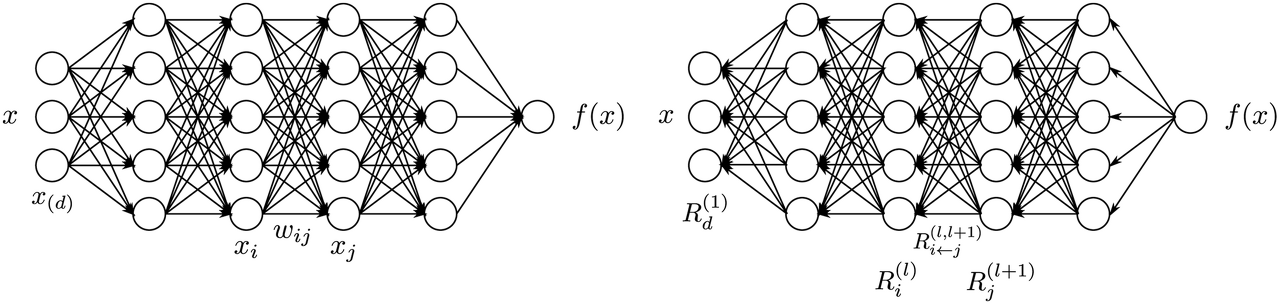
Common Mapping from one layer to next layer consists of a linear projection followed by non-linear function.

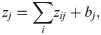

w_ij is a weight connecting x_i and x_j and g is a non-linear activation function.
1. Talyer-type Decomposition


2. Layer-wise relevance backpropagation
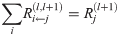


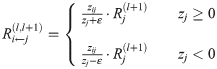


My thoughts of today’s reading:
Trying to understyand the mathematical expression was difficult but was able to help the overall understanding of
LRP. I did't explain in detiail LRP about Multilayer Networks due to lack of understanding. I want to study about it and make a notebook about LRP with Pytorch or Tensorflow.
Reference:
- 안재현,『XAI: 설명 가능한 인공지능, 인공지능을 해부하다.』, 위키북스, 209~242pg
- Bach, Sebastian, et al. “On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation.” PLOS ONE, edited by Oscar Deniz Suarez, vol. 10, no. 7, 2015, p. e0130140. Crossref, doi:10.1371/journal.pone.0130140
- 공돌이의 수학정리노트, https://angeloyeo.github.io/2019/08/17/Layerwise_Relevance_Propagation.html
- Montavon, Grégoire, et al. “Explaining Nonlinear Classification Decisions with Deep Taylor Decomposition.” Pattern Recognition, vol. 65, 2017, pp. 211–22. Crossref, doi:10.1016/j.patcog.2016.11.008.
'Machine Learning' 카테고리의 다른 글
| Pygame 을 이용한 딥러닝 모델 시각화 툴 개발 (2) | 2021.12.26 |
|---|---|
| [XAI Reading Log] The All Convolutional Net #1 (0) | 2021.09.09 |
| [XAI Reading Log] Layer-Wise Relevance Propagation #1 (2) | 2021.08.26 |
| Monocular Depth Estimation (0) | 2021.08.18 |
| Convolutional Neural Network, 그 내부를 보다 (2) | 2021.07.28 |



