
러닝머신 하는 K-공대생
Convolutional Neural Network, 그 내부를 보다 본문
1. 글을 시작하며
CNN(Convolutional Neural Network)이 등장하고 이미지 분석에 대한 접근법은 완전히 바뀌었다고 해도 과언이 아니다. 그중 이미지 분할(Image Segmentation)은 사진/영상 내 특정 영역이 탐지하고자 하는 범주 중 어떤 범주에 속하는지 예측하는 것으로 의료, 드론, 무인 자동차 등 다양한 곳에서 사용된다. Image Segmentation은 보통 지도 학습으로 진행이 되는데 이미지 분류와 같이 특정 사진에 대한 정답이 필요하며 구체적으론 픽셀 별로 탐지하고자 하는 범주가 입력된 출력 변수가 필요하다. 본인은 정보 R&E를 진행하면서 복도 영역을 추출하기 위한 딥러닝 모델 학습을 위해 이미지 라벨링을 진행하였고 18시간 동안 약 2100장의 데이터셋을 구축하였고 딥러닝 모델을 학습에 사용하기도 했다. 이것은 사람이 할 짓이 아니다. 정부에서 이거와 관련해 일자리 창출을 하겠다는데 할 사람이 있을까..?

일반적으로 Image Segmentation 모형은 무수히 많은 파라미터를 가지고 있어 작은 학습 데이터셋으론 파라미터의 최적 값을 찾기 힘들며 정답을 생성하는 인원수에 따라 이미지 이해에 차이가 발생하므로 생성한 데이터를 검토하는데도 많은 시간이 걸린다. 이렇게 이미지 분할 문제 해결을 위한 데이터셋 구축은 어려우며 이에 나는 CNN 모델이 이미지를 이해하는 방법에 초점을 맞추어 클래스 수준에서만 라벨링 한 데이터셋으로도 지도 학습 기반의 Semantic Segmentation과 비슷한 성능을 낼 수 있을까 궁금증을 가지게 되었다. 예전 R&E 멘토링 중 CNN을 시각화할 수 있는 CAM(Class Activation Map)을 소개해주셨는데 이를 영역 분할과 연결지을 수 있을 것으로 예상하고 CNN 구조를 해부학적으로 분석해보고 CNN 모델을 다양한 방법으로 시각화를 시도하고 이미지 분할을 진행하는 방법과 연결 지을 수 있을지 공부하고 고민해보았다.
2. Activation for each layer of CNN
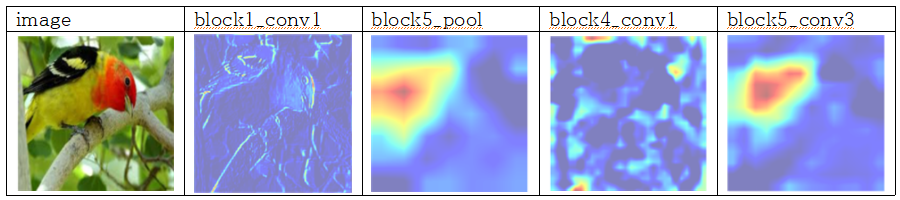
CNN의 모든 층을 보면서 입력으로 들어간 이미지가 각 레이어를 거치면서 어떻게 변화하는지를 확인하여 필터들이 어떤 영향을 주는지 이해해보고자 하였다. 복잡한 CNN 모델을 보면서 분석하기보다 근본적으로 각 Convolution Layer와 Max Pooling Layer 등을 거쳤을 때 어떻게 이미지가 표현되는지, 층이 깊어질수록 어떤 변화가 발생하는지를 확인하는 것이 목표이다. 이에 다음과 같이 CNN model을 구성하였고 Kaggle에서 제공하는 ‘Dogs vs. Cats’ 데이터셋을 이용하여 학습을 진행하였다. Flatten 레이어 이전까지의 입력에 대해 8개 층의 출력을 반환하였고 각 레이어의 필터마다 값을 증폭하고 0~255 사이 값을 갖는 부분만을 시각화하였고 의미를 파악해보았다.




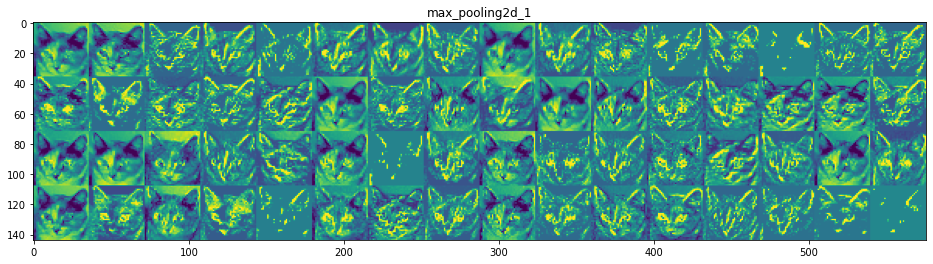


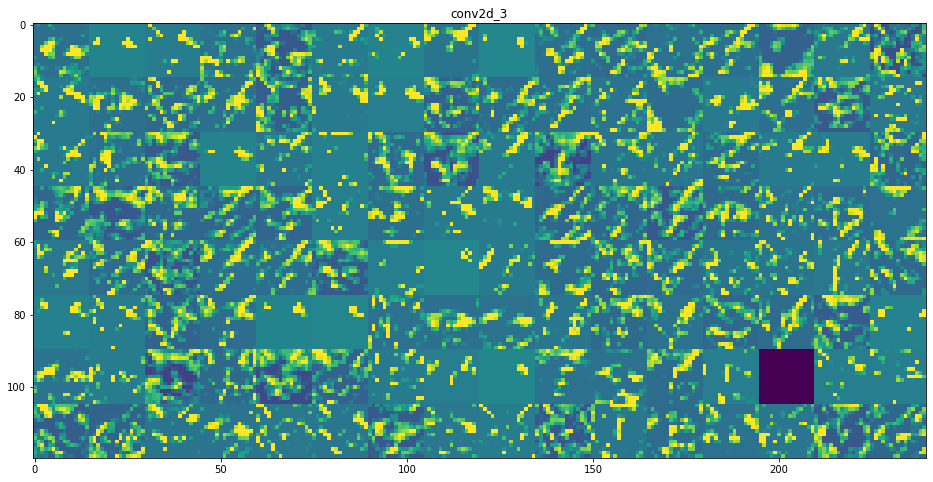
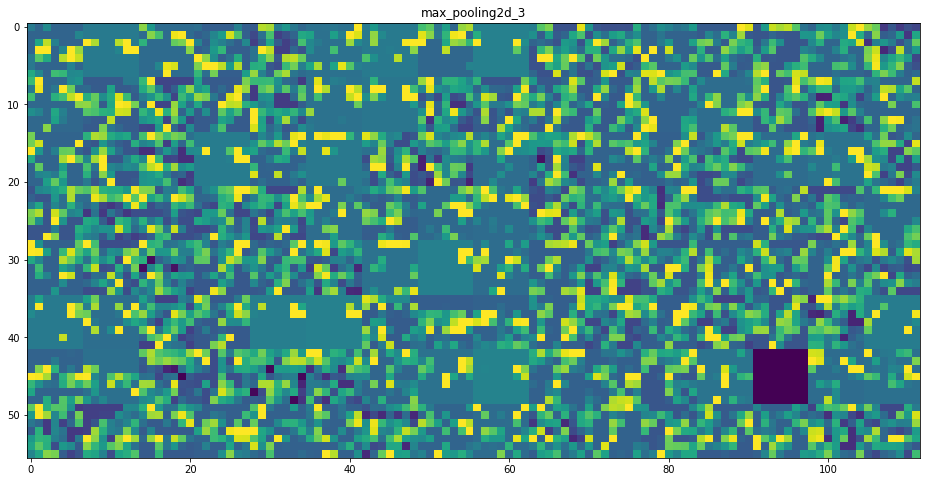
CNN 구조는 모델 층이 깊어질수록 더 구체적인 내용을 인식하고 얕은 층에서는 전반적인 특징을 추출하고자 함을 이해할 수 있다. 예를 들면 각 필터마다 얼굴, 눈, 코, 입 등 집중적으로 인식하는 부분이 다른 듯 말이다.
- 마치 첫번째 레이어는 Edge 검출을 위한 필터만을 모아든 것처럼 보인다.
- 상위 층으로 갈수록 활성화된 부분은 더욱 추상적이고 시각적으로 이해하기 어렵다. 귀와 눈처럼 고수준 개념을 인코딩하기 시작함을 확인할 수 있음. 상위층은 시각적 콘텐츠보다는 클래스에 대한 정보가 점점 증가함을 알 수 있다.
이미지 영역분할을 위한 아이디어를 여기서 떠올려 보자 하면 특정 부위를 보고 활성화하는 부위가 있는데 이를 잘 조합하면 특정 클래스의 활성 부위를 얻어낼 수 있지 않을까 고민할 수 있다.
3. Visualizing Filter Pattern
2에서 실행한 cat, dog 이진 분류 데이터셋에 대해 간단한 구조를 가진 모델을 넣어 아웃풋을 확인했으니 실제 이미지 분석에 자주 쓰이는 Imagenet 데이터셋에 대해 학습된 VGG16 모델을 불러와 각 레이어별 필터를 시각화한다. 이때 입력 이미지에서 시작해 특정 필터의 응답을 최대화하기 위해 입력 손실 텐서를 정의하고 입력에 대한 손실의 그래디언트를 계산한 후 정규화하여 경사 상승법을 적용하여 필터 활성화를 최대화하는 패턴을 이미지 텐서로 출력해보았다.


- Convolution Layer는 여러 필터의 조합으로 입력을 표현할 수 있는 일련의 필터를 학습한다. (푸리에 변환으로 신호를 코사인 함수로 분해하듯)
- 이 필터들은 모델의 상위 층으로 갈수록 점점 복잡해지고 개선된다.
- https://www.youtube.com/watch?v=ghEmQSxT6tw&ab_channel=DataCouncil를 참고하여 결과를 이해하면 좋다.
4. Class Activation Map (CAM)
기본적인 CNN구조에서는 Convolution layer로 특징을 뽑아내고 Fully-connected layer(FC)를 통과해 class class의 분류를 수행하게 된다. 이때 FC를 통과시키기 위해서 Convolution을 이용해 뽑은 특징점의 Flatten 과정을 거치게 되고 위치 정보들이 소실된다. 만약 이러한 위치 정보들이 소실되지 않고 유지되어서 class 분류를 수행한다면, CNN이 각 class를 분류하는데 중요한 위치정보를 알아낼 수 있을 것이다. ‘Learning Deep Features for Discriminative Localization’에서는 특징점의 Flatten 과정 대신 각 채널별로 Global Average Pooling(GAP)을 적용하는 방법을 이용하여 class의 분류를 수행한다. n번재 채널의 정보가 어떤 클래스에 얼마나 영향을 미치는지 가중치로 나타나게 되고, 이를 각 채널들과 곱하여 더해주면 n번째 클래스에 영향을 미치는 위치정보 즉, class activation map을 알 수 있다.
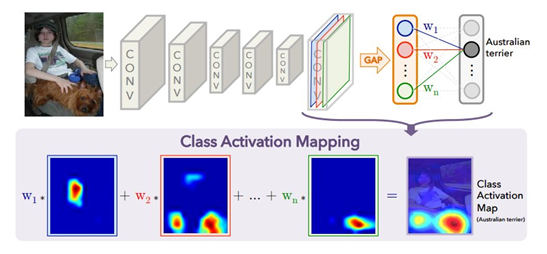
이를 수식적으로 표현해보면 k번째 채널의 값들 중 (x, y)에 위치한 값을 라고 하고 GAP을 거친 값을 $F^{k}=\sum _{x,y}f_{k}\left( x,y\right)$, 클래스 c에 대해 softmax 입력으로 주어지는 값 $S _{c}=\sum _{k}w_{k}^{c}F^{k}$ 라고 표현하면 가 k번째 채널과 클래스 c에 대하는 값이라면 $w_{k}^{c}$ 는 클래스 c에서 $F^k$의 중요성을 나타낸다. $S_c$ 에서 $F^k$를 풀어 정리하면 $S_{c}=\sum _{x,y}\sum _{k}w_{k}^{c}f_{k}\left( x,y\right)$ 이며 $L_{CAn}^{c}\left( x,y\right) =\sum _{k}w_{k}^{c}f_{k}\left( x,y\right)$ 으로 클래스 c에 대한 CAM을 나타낼 수 있다. 즉, 수식적으로 정리해보면 $L_{CAn}^{c}\left( x,y\right)$ 는 (x,y)에 위치한 값이 클래스 c로 분류되는데 미치는 중요도로 해석할 수 있다.
이 CAM을 통해 R&E에서 계단 인식을 위해 학습했던 MobileNetv2의 마지막 Conv Layer의 시각화를 시도하였다. GAP을 적용하고 모델을 재학습하여 GAP 뒤에 위치한 Dense Layer의 $w_{k}^{c}$를 받아와 위 수식대로 연산을 진행하여 CNN을 시각화하였다. CAM은 한계가 있는데 FC를 GAP으로 대체해야 하며 GAP 바로 직전의 컨볼루션 레이어만 사용할 수 있다는 점과 GAP 뒤에 위치한 Dense Layer에서 $w_{k}^{c}$ 정보를 받아야 하므로 모델을 다시 fine-tuning 시켜야 한다. https://github.com/taegukang35/device_for_blind/blob/main/stair_cam.ipynb 참고.

5. Grad-CAM
4에서 CAM은 GAP으로 바꾸고, GAP 직전의 Convolution Layer만 쓸 수 있으며, GAP 이후에 존재하는 Dense Layer의 가중치들을 가져와야 하기 위해 재학습을 진행해야 한다. 이에 관련 논문 조사를 진행해보았으며 ‘Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization’을 참고하면, Grad-CAM은 CAM의 보다 일반화된 버전으로 Grad-CAM은 GAP이 없어도 쓸 수 있으며, Grad-CAM은 마지막 Convolution Layer에 한정되지 않고, gradient를 weights로부터 사용하기 때문에 CAM에서 차원이 맞지 않는 문제로부터 자유롭다. Grad-CAM 기법에서 뉴런 중요도 가중치는 $a_{k}^{c}=\dfrac{1}{Z}\sum _{i}\sum _{j}\dfrac{\delta y^{c}\cdot }{\delta A_{ij}^{k}}$ 로 구해지며 마지막 conv layer로 들어오는 기울기 정보 $\delta A_{ij}^{k}$ 는 $y^c$가 $A^k$ 에 가지는 가중치, $a^k$ 는 타켓 클래스 c에 대한 k번재 피쳐맵이 가지는 중요도, $A^k$는 어떤 layer의 k번째 피처맵을 의미할 때 Grad-CAM인 $L_{Grad-CAM}^{c}=ReLU\left( \sum _{k}a_{k}^{c}A^{k}\right)$ 로 구할 수 있으며 ReLU는 음수를 0으로 치환하는 연산이다.
이것을 활용해 CNN의 FC이전 레이어들의 CAM을 얻어내며 특징을 분석하고, cv2.threshold를 이용해 threshold를 잡아 이진화시켜 마스킹을 진행하고 cv2.findCountours를 이용해 Contour를 그리고, Contour중 가장 바깥쪽을 기준으로 bounding box를 생성하였다.
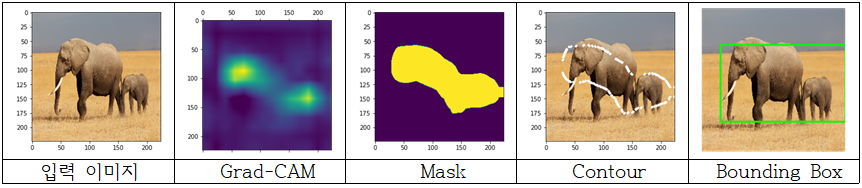
기존 CAM의 단점을 극복하기 위한 Grad-CAM을 이해하고 구현을 진행하였다. 레이어가 깊어질수록 물체의 영역을 인지하고 검출이 되기 시작했으며 너무 얕은 층에서의 CAM은 segmentation에 적합하지 않으며 마지막 컨볼루션에서의 CAM이 이미지 특성을 가장 잘 잡았음을 알 수 있었다. 각 층별로 Grad-CAM을 합쳐서 물체 전체의 영역을 커버할 수 있지 않을까 생각했지만 이는 힘들다는 것을 시각화를 통해 확인할 수 있었다. Grad-CAM이 이미지의 특징이 되는 부분을 집중적으로 잡아주고 물체의 전체 부위를 마스킹하지 않기 때문에 Grad-CAM을 사용할 때 영역을 넓히는 방법을 고민해야 함을 알 수 있다.
그럼에도 단순 이미지 카테고리만 라벨링 된 데이터로 학습된 CNN 모델으로부터 대략적인 Mask를 알아낼 수 있었고, Grad-CAM을 기반으로 Contour를 잡았으며 나아가 Bounding Box까지 추출해낼 수 있게 되었다는 점에서 Grad-CAM의 유용성을 확인해볼 수 있다.
6. Guided Backpropagation
‘Guided Backpropagation’은 ‘Striving for Simplicity: The All Convolutional Net’ 논문에서 제안된 시각화 방식으로 이전에 제안된 ‘deconvnet’이 MaxPooling 레이어를 거슬러 올라 최댓값을 가진 부분 피쳐맵이 어디인지 기억하는 indices가 필요하며 시각화된 결과가 좋지 않아 이를 극복하기 위해 제안된 개념이다. Maxpooling layer를 스트라이드가 2 이상의 Conv Layer로 대체하여 뒤 부분 레이어의 그래디언트뿐 아니라 현재 레이어의 relu값도 사용하므로 시각화 결과가 깔끔하다는 장점이 있다.
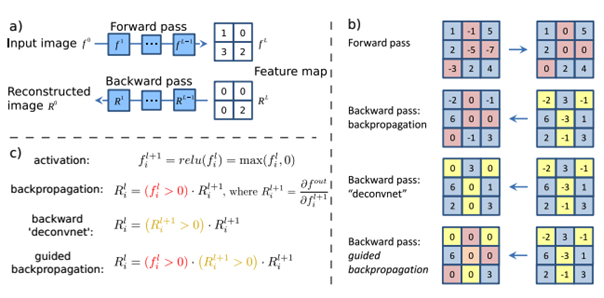
Guided backpropagation은 backpropagation과 deconvnet을 결합한 형태로, 어떤 하나라도 음수라면 그 값을 0으로 처리하게 되며 다른 방법에 비해 더 작은 수의 gradient를 이미지 재구축에 사용하게 된다. 이를 구현하기 위해 GuidedBackProp 함수를 registry에 등록하고 새로운 텐서플로우 그래프를 만들어 기존 ‘Relu’의 gradient를 GuidedBackProp으로 업데이트시켰고 평균을 0, 표준편차를 0.1로 normalize한후 클리핑 후 RGB 값으로 바꿔주어 시각화를 진행하였다.
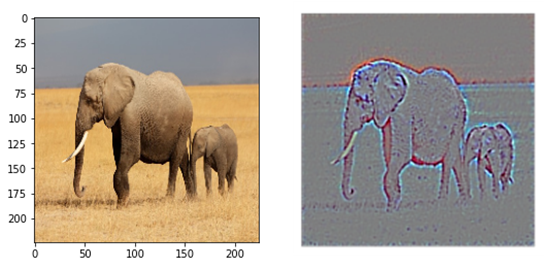
7. Guided Grad-CAM
5에서 Grad CAM은 특정 클래스의 위치정보를 얻을 수 있었고, 6에서 Guided Backpropagation을 진행했을 때는 특정 클래스의 윤곽선을 따낼 수 있었다. 이 둘을 합쳐 윤곽을 Guided Backpropagation을 이용해 추출하고, 클래스에 특화된 부분을 Grad-CAM으로 마스킹하여 기존 Grad-CAM이 만드는 히트맵이 뚜렷한 이미지를 생성할 수 없다는 단점을 극복하고자 하였다. 둘이 합치는 방법은 Guided Backpropagation을 통해 만들어낸 saliency에 Grad-CAM의 결과를 곱하여 구현할 수 있다.
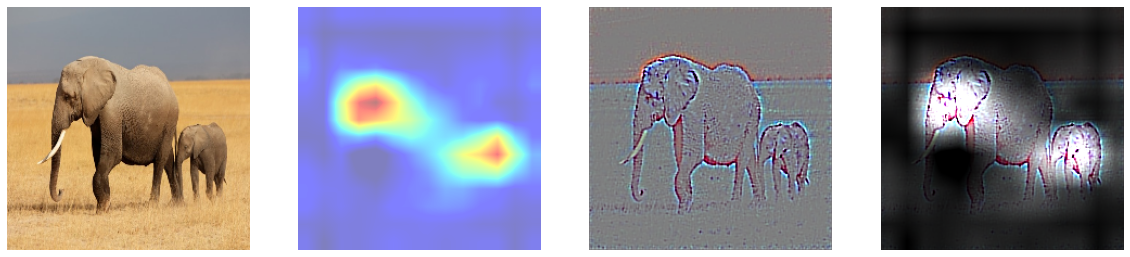

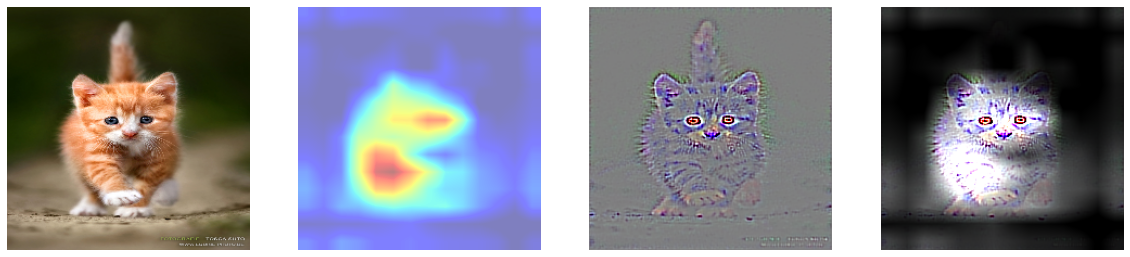
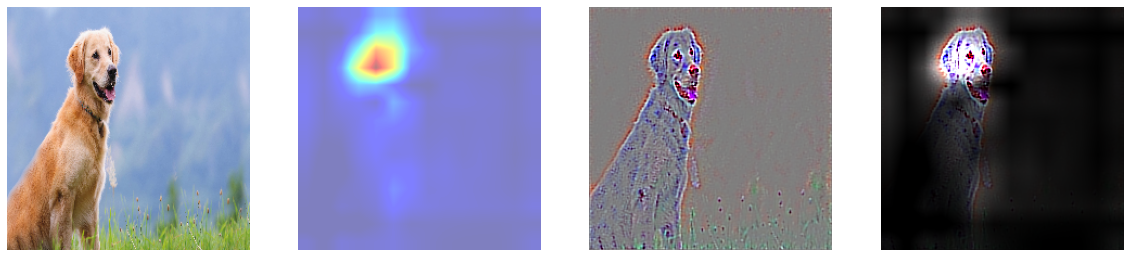
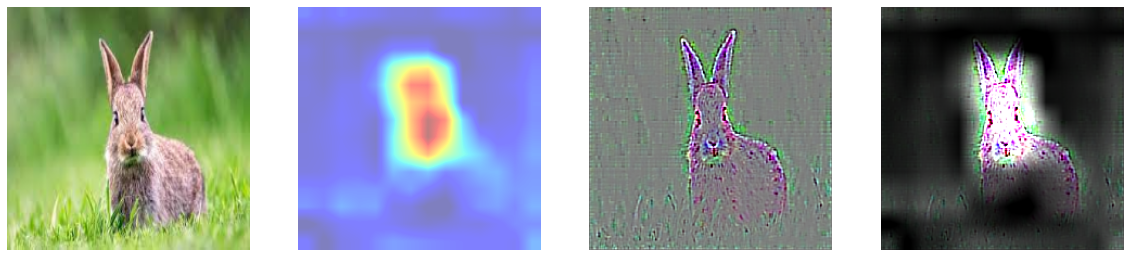
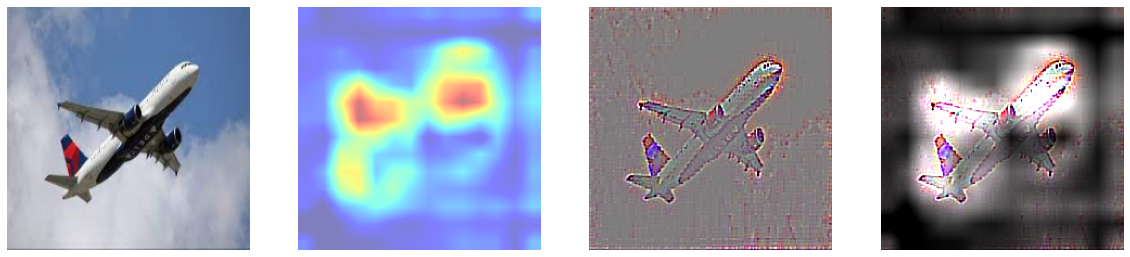
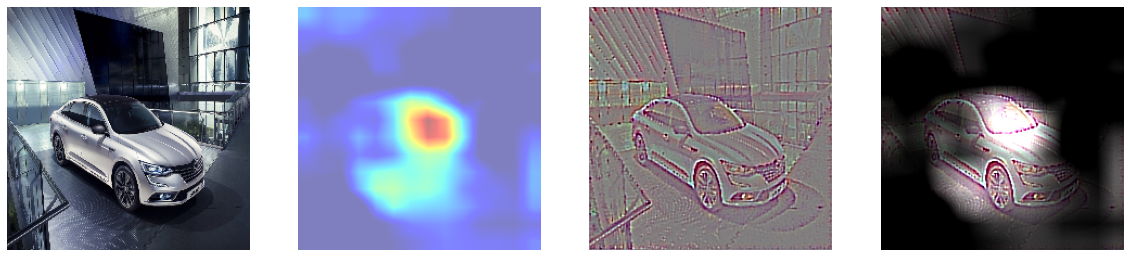
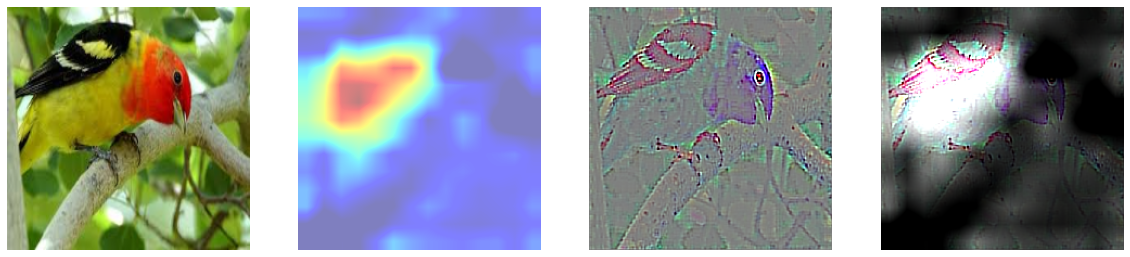
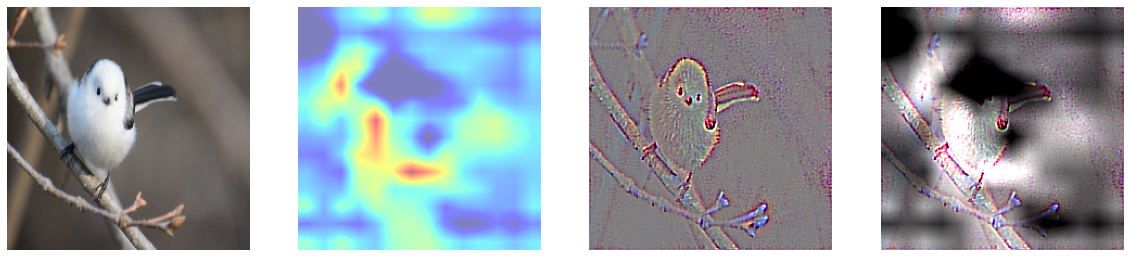
8. Weakly Supervised Semantic Segmentation
서론에 언급했듯 사실 내가 풀려고 했던 문제와 동일한 주제로 연구를 진행하는 분야가 있다. 사실 되게 최신의 연구분야고 용어만 들어봤지 자세히 바보니 정확히 내가 원하던 바이다. 바로 Weakly Supervised Semantic Segmentation
Weakly Supervised Semantic Segmentation(WSSS) 연구 목적은 상대적으로 작은(Weakly) 정보로 Semantic Segmentation을 수행하는 것이 목표이다. http://dmqm.korea.ac.kr/activity/seminar/293 세미나 영상을 정리해보았다.
weakly supervision에도 여러 타입이 있는데 첫 번째는 범주와 위치이다. ‘Simple Does It: Weakly Supervised Instance and Semantic Segmentation’ 논문이 대표적이다. 픽셀 단위 라벨링에 비해 위치를 지정해주는 것은 상대적으로 간단하여 범주와 범주의 위치를 이용해 Semantic Segmentation을 진행하는 것이다. 학습 데이터셋에 대해 1 Epoch 학습 후 정답 이미지 교체를 진행하고 범주별로 예측 결과와 위치 상자와 비교해 작은 것을 정답으로 선택하여 이를 반복한다.
2번째 타입은 범주 정보 기반(image-level annotation)이다. 입력 이미지마다 어떠한 범주가 존재하는지에 대한 정보만 존재하고 이미지 분류 모델을 사용해 Segmentation Map을 생성하고자 하는 것이다. 입력 이미지에 대해 어떠한 범주가 있는지를 예측할 수 있는 모형을 구축하고 특정 범주를 예측할 때 입력 이미지의 어떤 부분을 보고 예측하는지 파악이 필요하다. 이것을 해줄 수 있는 알고리즘이 Gradient-weighted Class Activation Mapping(Grad-CAM)이다. Grad-CAM을 이용해 특정 객체의 위치를 파악할 수는 있지만 정확히 객체가 존재하는 영역을 인식하고 분류하는 것은 아니다. 확률 값과 입력 이미지를 이용해 정확히 객체 존재 영역을 탐지해야 한다. 이를 위한 것이 Dense Conditional Random Field이다. Dense CRF 알고리즘의 입력 변수는 픽셀별 확률 값과 이미지이다. 픽셀별 확률 값은 Grad-CAM을 이용해 생성하고 모든 픽셀은 같은 범주에 속할 수 있다는 가정 아래 픽셀별 객체 존재 확률과 색상을 기준으로 객체의 경계면 가장자리를 탐색하여 특정 범주에 대한 존재 확률이 가장 큰 범주를 해당 픽셀에 대한 범주로 할당한다.
CVPR등에 개제 된 여러 논문을 분석해보면 이 분야의 Self-Supervised Learning(자가 학습) 방법론을 이용하여 성장하고 있는 경향이 있어 보인다.. 입력 데이터의 특징을 이해하고 있는 가중치를 학습하여 해결하고자 하는 문제 상황에 적합한 모델과 결합하여 기존보다 성능 향상을 도모한다. ‘Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation’ 논문에선 동일한 이미지에 대해 이미지 크기가 변한 경우 활성 영역이 변경된다는 CAM의 문제점을 지적하며 자가 학습을 이용해 기존 CAM을 개선하여 객체 가장자리에 가깝게 활성 영역을 생성하였다. ‘Weakly Supervised Semantic Segmentation via Sub-Category Exploration’ 논문에서는 새롭게 생성한 레이블은 입력 이미지의 추출된 특징을 군집하여 생성하고 기존 레이블과 새로운 레이블을 동시에 분류하여 입력 이미지에 대한 정확한 이래를 진행한다. 이 방법으로 CAM 성능이 증가할 것으로 기대하고 방법론을 개발하여 높은 성능을 보여주었다.
9. 글을 마무리하며
첫 머신러닝에 대한 글을 포스팅이다. 블로그명에 맞는 글을 제대로 써보는 것 같아 뿌듯하다. 나의 작은 궁금점에서 시작해 CNN에 대한 깊은 이해와 WSSS 등 최신의 연구분야까지 방대한 내용을 다룬 것 같아 정리하면서 많은 도움이 된 것 같다. 아마 CNN에 어느 정도 이해를 한 상태로 이 글을 읽는다면 흥미로운 글일 것으로 예상한다. CNN을 잘 모른다면 혼란의 도가니이겠지만..!
CNN 모델 시각화 과정을 통해 CNN모델 구조에 대한 이해와 Image Segmentation에 대한 아이디어를 얻을 수 있었다.
필터 시각화를 통해선 CNN이 물체를 이해하는 방식에 대해 깊게 생각해볼 수 있었으며, CAM과 관련해선, 레이어가 깊어질수록 물체의 영역을 인지하고 검출이 되기 시작했으며 너무 얕은 층에서의 CAM은 segmentation에 적합하지 않으며 마지막 컨볼루션에서의 CAM이 이미지 특성을 가장 잘 잡았음을 알 수 있었다. 각 층별로 Grad-CAM을 합쳐서 물체 전체의 영역을 커버할 수 있지 않을까 생각했지만 이는 힘들다는 것을 시각화를 통해 확인할 수 있었다. Grad-CAM이 이미지의 특징이 되는 부분을 집중적으로 잡아주고 물체의 전체 부위를 마스킹하지 않기 때문에 Grad-CAM을 사용할 때 영역을 넓히는 방법을 고민해야 함을 알 수 있다. 그럼에도 단순 이미지 카테고리만 라벨링 된 데이터로 학습된 CNN 모델으로부터 대략적인 Mask를 알아낼 수 있었고, Grad-CAM을 기반으로 Contour를 잡았으며 나아가 Bounding Box까지 추출해낼 수 있게 되었다는 점에서 Grad-CAM의 유용성을 확인해볼 수 있다. 또한 Guided backpropagation과 Grad-CAM을 이용해 추출한 Mask의 경우에는 Semantic Segmentation 뿐만 아니라 모델이 잘못된 방향으로 학습되거나 여러 이미지가 동시에 존재할 때 특정 이미지만을 검출했을 때 왜 그런 판단을 내렸는지 진단할 수 있을 것이다.
- 필터 시각화 + Grad-CAM: https://github.com/taegukang35/ML-study/blob/main/keras_CNN_total.ipynb
- Guided Grad-CAM : https://github.com/taegukang35/ML-study/blob/main/Guided_Grad_CAM.ipynb
Weakly Supervised Semantic Segmentation은 굉장히 흥미로운 분야이다. 이 분야의 연구 동향을 파악하기 위해 랩실 세미나 영상도 찾아보고 많은 논문들과 읽어보며 이해가 안 되는 논문들은 블로그에 정리된 글을 보거나 발표 영상을 보면서 이해를 시도하였고 카테고리화 정리하였다. 논문을 정리하면서 CNN 모델이 이 WSSS 분야와 관련된 연구가 매우 활발히 진행되고 있는데 나와 비슷한 고민에서 시작된 연구가 불과 몇 년 안 된 사이에 성과를 보이고 있다니 신기했고 내가 접근했던 어텐션 방법과 Grad-CAM의 활성화 부위를 넓히는 방법론을 활용하여 Semantic Segmentation을 진행하고자 하는 시도가 많았다. 이미지에 초점을 맞추어 Weakly supervision에 대해 많은 연구가 진행되고 있는데 다른 text데이터나 센서 데이터 등에 대해서도 Weakly Supervision과 비슷한 연구가 없을까 궁금하다. 딥러닝 관련 논문을 많이 못 읽어봤었는데 이번 기회에 각 잡고 여러 번 반복해서 시간을 투자하여 읽어보았다. 수식적인 부분이 많이 어려웠고 이걸 어떻게 구현할지도 솔직히 감이 안 잡히는 부분이 많다. 이번에 이해한 논문들을 직접 구현해보면서 내 블로그에 정리해두고자 한다. 블랙박스라 불리는 딥러닝 모델의 내부를 해석하는 것도 꽤나 재밌는 것 같다. 최근에 XAI관련 책도 구매를 했으니 앞으로 Computer Vision 에만 갇히지 말고 XAI 분야에 대한 공부도 진행하고 싶다.
마지막으로 이번 포스팅과 관련하여 두 개의 영상을 추천하며 이 글을 정말 마치겠다. 긴 글 읽어준 여러분께 감사하다 :)
참고 문헌:
[1] 프랑소와 숄레, 『케라스 창시자에게 배우는 딥러닝』, 길벗, 219~240pg
[2] Zhou, Bolei, et al. "Learning deep features for discriminative localization." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016
[3] Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, Dhruv Batra, Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. 2016
[4] Jost Tobias Springenberg, Alexey Dosovitskiy, Thomas Brox, Martin Riedmiller, Striving for Simplicity: The All Convolutional Networks. 2014
[5] Anna Khoreva, Rodrigo Benenson, Jan Hosang, Matthias Hein, Bernt Schiele, Simple Does It: Weakly Supervised Instance and Semantic Segmentation. 2016
[6] Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, Xilin Chen, Self - supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation. 2020.
[7] Yu-Ting Chang, Qiaosong Wang, Wei-Chih Hung, Robinson Piramuthu, Yi-Hsuan Tsai, Ming-Hsuan Yang, Weakly-Supervised Semantic Segmentation via Sub-category Exploration. 2020.
'Machine Learning' 카테고리의 다른 글
| Pygame 을 이용한 딥러닝 모델 시각화 툴 개발 (2) | 2021.12.26 |
|---|---|
| [XAI Reading Log] The All Convolutional Net #1 (0) | 2021.09.09 |
| [XAI Reading Log] Layer-Wise Relevance Propagation #2 (1) | 2021.09.02 |
| [XAI Reading Log] Layer-Wise Relevance Propagation #1 (2) | 2021.08.26 |
| Monocular Depth Estimation (0) | 2021.08.18 |



